Do you remember when that (false?) factoid about Newton having made his greatest discoveries during the bubonic plague was circulating at the beginning of quarantine?
Well, this was my bubonic plague moment.
What if we…
It all started when I was chatting with one of my friends about those funny predictive text Bots that write TV show scripts. As we were talking I had a brain blast: It would probably be relatively easy to create a Bot that writes Rupi Kaur poems. As it turns out, this idea was so good that it had been done before . Yet, still the thought lingered with us. And then the real idea hit me: The Bachelor.
Among my friends, there are three seasons: The Bachelor, The Bachelorette, and Is the Bachelor back yet? Let me stress, we count ourselves among the Bachelor fans who watch the show as a social activity. Let me also stress, anyone who tells you they watch the Bachelor as a social activity is definitely hiding something.
In any case, the plan was set in motion. We didn’t have interest in recreating Bachelor scripts as much as we did the aura of the contestants themselves. In fact, we didn’t want to just create Bot contestants. We wanted to become Bot contestants. The final product of this project would be a quarantine-born episode of the Bachelor.
Manifesting the dream
So I went to work. My first approach was based off of the text projects I was inspired by. I knew these projects started with a corpus. For my corpus, I knew exactly where to start. ABC posts bios of Bachelor contestants online.[1]
My first step was to scrape the bios and description of each contestant. If you’re interested in learning more about Webscraping, I wrote a tutorial on the basics . If you’re looking to replicate these methods with a different corpus, it is important to always check the User Agreement, especially if you’re going to Webscrape data.
Magic in the methods
Now its time for the real magic of this process: the methods. One of the best examples of predictive text is Botnick’s Voicebox. Voicebox analyzes a selected text corpus to predict word patterns. With the help of human editors, Botnick produces humorous content parodying everything from TV shows, to song lyrics, to novels.
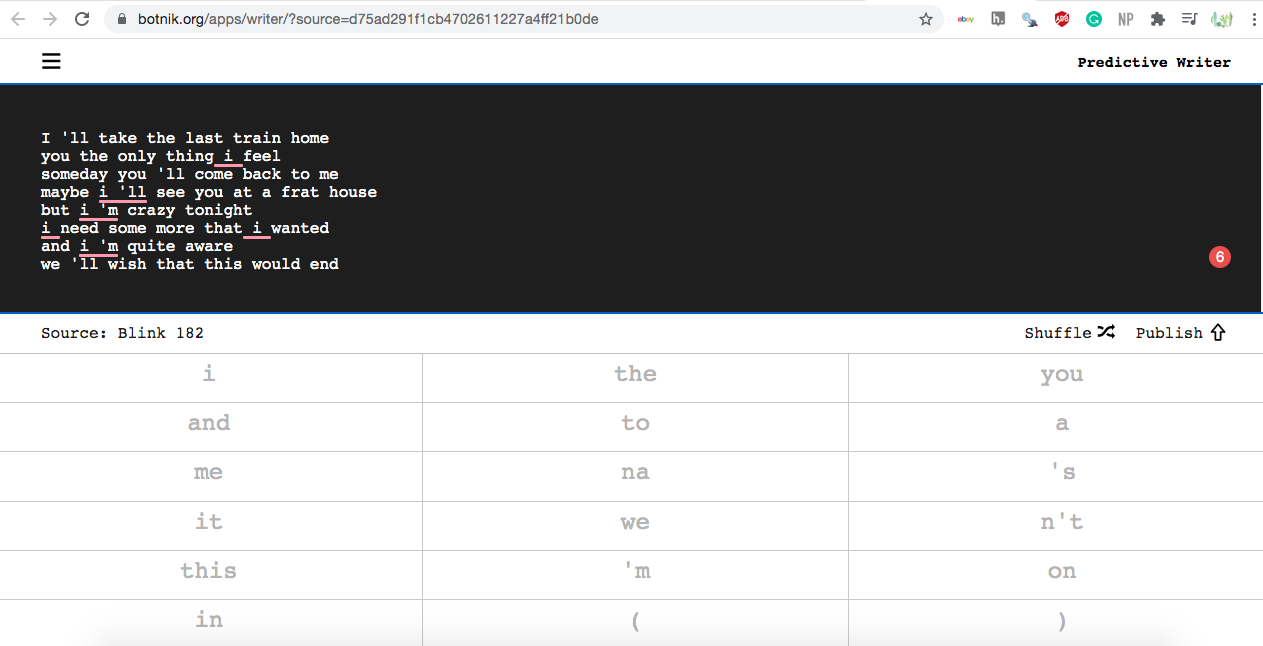
The method behind Botnick, and many other predictive text generators, is Markov-Chains. Ben Shraver wrote an excellent Medium post about Markov Chains and how they can be used in these predictive text analyses. Basically, Markov Chains use probabilities to predict future events in sequences. Like any machine learning method, Markov Chains need to be fed training data, which is this case is a text corpus. A Markov Chain model, then, will attempt to predict future events in a sequence based of the known sequence patterns in the training data. In the case of text, an algorithm learns common word pairings and sentence structures to predictively create new text. Botnick calls this a “voice,” which is essentially an algorithm that “writes” in the style of a character, musician, etc.
So I got to work implementing MC methods on my corpus of Bachelor biographies, but it didn’t turn out exactly how I expected.
Not your typical training montage
Like I mentioned earlier, these predictive text methods rely heavily on training data. So, if you’re creating an episode of Seinfeld, a blink-182 album, or a new Harry Potter chapter, your going to have better results because of the amount of training text available to create that voice. Unfortunately for me, around 90 biographies of training data wasn’t quite enough to satisfy my clients. Here’s the best of what my Bot came up with:
"Bunny Shes looking for her heart and hand Tattoos No dogs She has it the Mormon culture but neither one Bachelor with drug addiction Victoria could break any kind of her to talk interact with her biological mother and are you Dinner and cut her lease was the west"
Taking creative co-writing liberties, I came up with something like this.
Bunny is looking for someone to take her heart and hand. She has tattoos, but none of dogs. Her two tattoos ground her in her love of Mormon culture, but neither one depict the Bachelor with his drug addiction. She will break anyone who stands in the way of her talking to and interacting with biological mother, Victoria, at dinner. She is so committed to finding love that she ended her lease to move out West.
Like I said, according to my clients, this was not satisfactory. If we were going to produce a full episode of the Bachelor, we were going to need more character depth than these methods could give us.
Back to the excel spreadsheet
I was crushed that my very own Bot was unemployed. Still, I didn’t lose sight of our goal and determination to see this through. My clients wanted more creative control and I was going to give it to them.
I ended up going back to the basics, a good ol’ spreadsheet, to see this project through. I asked my friends to contribute possible ideas to personality categories: names, ages, occupations, hometowns, traits, interests, dating history, and sob story. Once we had a sufficient number of ideas, I used the RANDBETWEEN() function to randomly select one of the submissions from each category to create a character for each of us.
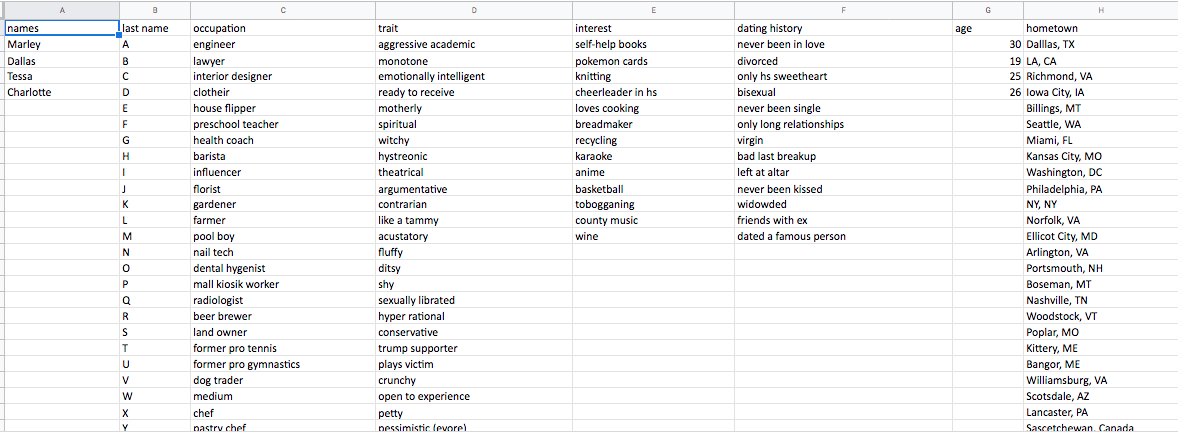
This method ended up working really well. We all had so much fun with our characters and developing a story. Though it was really fun to learn more about predictive text methods, I think this project taught me that most of the time human creativity just can’t be beat.
[1] Since I originally completed this project, ABC has actually archived the Bachelor bios I was working with. This is a really good learning lesson for anyone getting into Webscraping. The Web is constantly changing. If sustainably updating data is important to your project, Webscraping is probably not the tool to best accomplish your data collection.
Appendix
Here is the code I used to create the Bachelor bot!
## Create bot descriptions ---------
bios <- unlist(bios)
## text <- text[nchar(bios)]
text <- str_replace_all(bios, "[[:punct:]]", "")
terms <- unlist(strsplit(text, ' '))
fit <- markovchainFit(data = terms)
new1 <- NULL
for(i in 1:100){
new1 <- c(new1,
c(paste(markovchainSequence(n=50, markovchain=fit$estimate), collapse=' ')))
}
head(new1)
view(new1)
### Create bot input -------------
descriptions <- unlist(descriptions)
## text <- text[nchar(descriptions)]
text <- str_replace_all(descriptions, "[[:punct:]]", "")
terms <- unlist(strsplit(text, ' '))
fit <- markovchainFit(data = terms)
new1 <- NULL
for(i in 1:50){
new1 <- c(new1,
c(paste(markovchainSequence(n=5, markovchain=fit$estimate), collapse=' ')))
}
head(new1)
view(new1)